The question is: If you flip 

This is one that comes up periodically on Reddit, and I’ve answered it, though I’m not 100% I’ve always answered it exactly the same way twice. I do know that my answers to this one tend to be a little long and messy. To make a long story short, I always use some version of a recursive approach.
So the purpose of this article is to introduce the idea of recursive probability calculations, for problems which don’t seem amenable to another approach.
It interests me because it seems like there should be a simple formulation, but I always have to work out a fairly complicated approach. I’ve observed over the years that with counting problems there are almost always multiple approaches, and often one that’s quite elegant and simple. I suspect that’s the case here, but if so the alternate methods have so far eluded me.
Anyway, my approach is to use recursion, and if you haven’t seen a recursive probability calculation, then you may find my long-way around useful.
Why is this so hard?
First let’s talk about what makes it hard. Let’s say 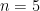

Well, not exactly. For instance HHHxx includes HHHHT, HHHHH, HHHTT and HHHHH. While xHHHx includes HHHHT, THHHT, HHHHH and THHHH. You’ll notice that two of those outcomes, HHHHH and HHHHT, are counted twice, and the pattern xxHHH includes other outcomes that have already been counted. So you wouldn’t just add up the four HHHxx outcomes, the four xHHHX, and the four xxHHH outcomes to say there are twelve ways this can happen. You’ve overcounted, which is always a danger in counting problems.
Now, there are well-established procedures for handling overcounting. First of all, you can try to construct your outcomes so that they don’t overlap. To make your outcomes mutually exclusive in other words. So we could use the pattern HHHTx and count those separately from HHHHx. There is guaranteed to be no overlap between HHHTx and xHHHx or xxHHH. With care, you could construct mutually-exclusive classes to count the outcomes for 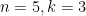
But when I try to do that for larger problems, say 
The other approach to overcounting is inclusion-exclusion. Suppose you want to count the number of things that fall in set A, or in set B or in set C, etc and those sets have overlap as those three patterns HHHxx, xHHHx, and xxHHH do. Then the inclusion-exclusion rule is that to calculate the total number of things in the union of those sets:
- Add up the membership of each individual set,
. We know we’re overcounting the overlaps, so next we
- Subtract the membership of each intersecting pair of sets,
. Each of those pairs is also counting things that belong to three or more sets, so we’ve over done the correction, which means we have to…
- Add the membership of triplets of sets,
- etc, alternating addition and subtraction (four sets, five sets, etc), until we’ve handled every combination.


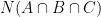

This seems to me even worse than trying to construct mutually-exclusive categories. Suppose there were 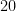
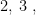

Again, there may be a different collection of events you could define and a clever inclusion-exclusion argument that’s tractable. But I haven’t found it yet. So that brings us to…
Recursive counting of coin flips
Recursive definition of anything is a pretty simple idea. You have a rule for defining higher terms (larger
The classic example used in teaching recursive computer programming is the factorial function. 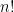


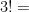


As another example, the Fibonacci numbers can be defined recursively as 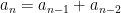

For instance, to use the recursive expression to evaluate 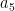


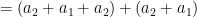
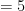


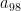
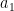

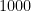
Let’s define 
First of all, 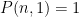

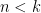
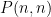

That handles the cases of 

- There is a run of
, probability
, or
- The last
flips are THH…H, probability
, and there is no run of length
, probability

This gives us the recursion
![\displaystyle P(n,k) = P(n-1,k) + \left ( \frac{1}{2} \right )^{k+1} \left[ 1 - P(n-k-1, k) \right ]](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+P%28n%2Ck%29+%3D+P%28n-1%2Ck%29+%2B+%5Cleft+%28+%5Cfrac%7B1%7D%7B2%7D+%5Cright+%29%5E%7Bk%2B1%7D+%5Cleft%5B+1+-+P%28n-k-1%2C+k%29+%5Cright+%5D+&bg=ffffff&fg=000&s=0&c=20201002)
Let’s see how this works with, for example, 
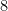
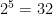

Recursively:
![\displaystyle \begin{aligned} P(5,3) &= P(4,3) + \left ( \frac{1}{2} \right )^{4} \left[ 1 - P(1, 3) \right ] \\[9 pt] &= P(4,3) + \frac{1}{16} [1 - 0] = P(4,3) + \frac{1}{16}\\[9 pt] &= \left \{ P(3,3) + \frac{1}{16} \left [1 - P(0,3) \right ] \right \} + \frac{1}{16} \\[9 pt] &= \frac{1}{8} + \frac{1}{16} + \frac{1}{16} = \frac{1}{4} \end{aligned}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cbegin%7Baligned%7D+P%285%2C3%29+%26%3D+P%284%2C3%29+%2B+%5Cleft+%28+%5Cfrac%7B1%7D%7B2%7D+%5Cright+%29%5E%7B4%7D+%5Cleft%5B+1+-+P%281%2C+3%29+%5Cright+%5D+%5C%5C%5B9+pt%5D+%26%3D+P%284%2C3%29+%2B+%5Cfrac%7B1%7D%7B16%7D+%5B1+-+0%5D+%3D+P%284%2C3%29+%2B+%5Cfrac%7B1%7D%7B16%7D%5C%5C%5B9+pt%5D+%26%3D+%5Cleft+%5C%7B+P%283%2C3%29+%2B+%5Cfrac%7B1%7D%7B16%7D+%5Cleft+%5B1+-+P%280%2C3%29+%5Cright+%5D+%5Cright+%5C%7D+%2B+%5Cfrac%7B1%7D%7B16%7D+%5C%5C%5B9+pt%5D+%26%3D+%5Cfrac%7B1%7D%7B8%7D+%2B+%5Cfrac%7B1%7D%7B16%7D+%2B+%5Cfrac%7B1%7D%7B16%7D+%3D+%5Cfrac%7B1%7D%7B4%7D++%5Cend%7Baligned%7D+&bg=ffffff&fg=000&s=0&c=20201002)
Here’s an implementation of the recursive calculation in Python.
def P(n, k):
if n < k:
return 0
elif n == k:
return 1/2**n
else:
return P(n-1, k) + (1 - P(n-k-1, k))/2**(k+1)and here is a function to generate all possible sequences of n coin flips and collect statistics on the longest sequence of heads found (the logical value True is coding for heads):
import itertools as it
import numpy as np
def seq_stats(n):
# All possible flips of length n
all_n_seqs = it.product({True, False}, repeat=n)
stats = np.zeros((n+1,), dtype=int)
for flips in all_n_seqs:
seq_len = 0
longest_seq = 0
for flip in flips:
if flip:
seq_len += 1
longest_seq = max(longest_seq, seq_len)
else:
seq_len = 0
# print(flips)
# print(f'Longest seq = {longest_seq}')
stats[longest_seq] += 1
return statsThis code runs a side-by-side comparison of the entire probability distribution for any n (takes about 10 seconds for n = 20).
# Do a side by side comparison of the two methods
def compare_methods(n):
t0 = time.perf_counter()
flip_stats = seq_stats(n)
# stats are P(>=k) so do the cumulative sum
empirical_stats = np.cumsum(flip_stats[::-1])[::-1] / 2**n
t1 = time.perf_counter()
theoretical_stats = [P(n,k) for k in range(n+1)]
t2 = time.perf_counter()
print(' k Empirical P(n,k) Theoretical P(n,k)')
for k in range(n+1):
print(f'{k:3d} {empirical_stats[k]:12.5f} {theoretical_stats[k]:12.5f}')and finally, here are the results for 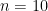
k Empirical P(n,k) Theoretical P(n,k)
0 1.00000 1.00000
1 0.99902 0.99902
2 0.85938 0.85938
3 0.50781 0.50781
4 0.24512 0.24512
5 0.10938 0.10938
6 0.04688 0.04688
7 0.01953 0.01953
8 0.00781 0.00781
9 0.00293 0.00293
10 0.00098 0.00098
Leave a comment