You might have heard of linear regression for fitting a straight line to data, such as in the picture below. But did you know that you can fit much more complicated functions to data, and the procedure is almost as simple? You may be surprised to learn that “linear” covers a lot more than straight lines. This article is looking at the general “linear least squares” problem. So why is it called “linear” then? We’ll get to that.
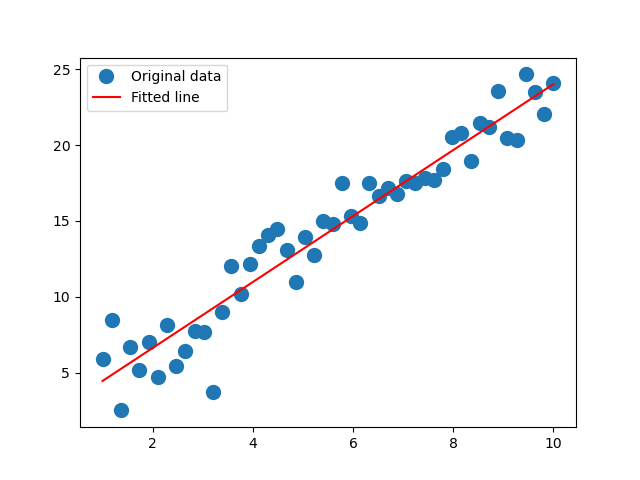
As we’ll see below, the math becomes a lot simpler but also more generally useful when we introduce Linear Algebra and matrices. But first we consider the common case of fitting a straight line, without the use of matrices.
That is, we do a straight line fit the hard way.
Linear Regression (straight-line fitting, non-matrix version)
Often we have data that is noisy as with the blue dots in the figure, and we are interested in the trend line. We believe that the “true” y data follows a straight-line relationship with respect to x,
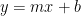
but has been corrupted by noise, so instead the observed y values are a little above or below the true y data.

where the term 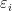
Statistics Note: (If statistical language triggers you, skip this paragraph.) For the statistical analysis of this procedure, you need to know that most commonly the errors are assumed to come from a normal distribution with mean = 0, and they are independent. Also, they all have the same standard deviation. If you drew the error bars, they would all be the same size. We’re not doing a statistical analysis, but you can assume we keep those assumptions because the “best” fit is different if they don’t hold.
Note that the equation above with the error term is for the purpose of the analysis. We don’t have access to the error value and the “true y”. All we have is a measured 


Statistics Note: In statistics terms, 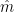



So what is the procedure? For any particular guess at the parameters 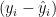
Some will be positive, some negative, so what we do is square them, and add them up. That gives us this quantity (assuming we have 

The 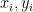
In other words, we are going to minimize the function E with respect to the variables 
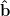
So that means we’re going to take the derivatives with respect to those variables and set them equal to 0.
First we expand E in terms of the parameters. For simplicity we’ll just write
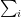

The n in the third term comes from the fact that we are adding a 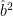
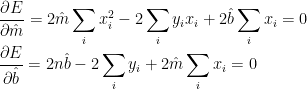
(Remember, the derivatives are with respect to the hatted parameters. The summations over data values are constants.) The second equation can be rearranged to

This can be used to find the value of 
![\displaystyle \hat{m} \sum_i x_i^2 - \sum_i y_i x_i + \frac {\left ( \sum_i y_i - \hat{m} \sum_i x_i \right )} {n} \sum_i x_i = 0 \\ \hat{m} \left [ \sum_i x_i^2 - \frac {\left (\sum_i x_i \right )^2}{n} \right ] - \sum_i y_i x_i + \frac {\left ( \sum_i y_i \right )\left ( \sum_i x_i \right )}{n} = 0 \\ \hat{m} \left [ n \sum_i x_i^2 - \left (\sum_i x_i \right )^2 \right ] - n\sum_i y_i x_i + \left ( \sum_i y_i \right )\left ( \sum_i x_i \right ) = 0](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Chat%7Bm%7D+%5Csum_i+x_i%5E2+-+%5Csum_i+y_i+x_i+%2B+%5Cfrac+%7B%5Cleft+%28+%5Csum_i+y_i+-+%5Chat%7Bm%7D+%5Csum_i+x_i+%5Cright+%29%7D+%7Bn%7D++%5Csum_i+x_i+%3D+0+%5C%5C++%5Chat%7Bm%7D+%5Cleft+%5B+%5Csum_i+x_i%5E2+-+%5Cfrac+%7B%5Cleft+%28%5Csum_i+x_i+%5Cright+%29%5E2%7D%7Bn%7D+%5Cright+%5D+-+%5Csum_i+y_i+x_i+%2B++%5Cfrac+%7B%5Cleft+%28+%5Csum_i+y_i+%5Cright+%29%5Cleft+%28+%5Csum_i+x_i+%5Cright+%29%7D%7Bn%7D+%3D+0+%5C%5C++%5Chat%7Bm%7D+%5Cleft+%5B+n+%5Csum_i+x_i%5E2+-+%5Cleft+%28%5Csum_i+x_i+%5Cright+%29%5E2+%5Cright+%5D+-+n%5Csum_i+y_i+x_i+%2B+%5Cleft+%28+%5Csum_i+y_i+%5Cright+%29%5Cleft+%28+%5Csum_i+x_i+%5Cright+%29+%3D+0+++&bg=ffffff&fg=000&s=0&c=20201002)
Giving us the standard linear regression equations:
![\displaystyle \hat{m} = \frac {\left [ n\sum_i y_i x_i - \left ( \sum_i y_i \right )\left ( \sum_i x_i \right ) \right ]} {\left [ n \sum_i x_i^2 - \left (\sum_i x_i \right )^2 \right ]} \\[6pt] \hat{b} = \frac{\left (\sum_i y_i - \hat{m} \sum_i x_i \right )}{n}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Chat%7Bm%7D++%3D+%5Cfrac+%7B%5Cleft+%5B+n%5Csum_i+y_i+x_i+-+%5Cleft+%28+%5Csum_i+y_i+%5Cright+%29%5Cleft+%28+%5Csum_i+x_i+%5Cright+%29+%5Cright+%5D%7D+%7B%5Cleft+%5B+n+%5Csum_i+x_i%5E2+-+%5Cleft+%28%5Csum_i+x_i+%5Cright+%29%5E2+%5Cright+%5D%7D+%5C%5C%5B6pt%5D++%5Chat%7Bb%7D+%3D+%5Cfrac%7B%5Cleft+%28%5Csum_i+y_i+-+%5Chat%7Bm%7D+%5Csum_i+x_i+%5Cright+%29%7D%7Bn%7D+&bg=ffffff&fg=000&s=0&c=20201002)
Whew! That was a heck of a lot of algebra!
Now watch how easy this becomes when we apply linear algebra.
Linear Regression (straight-line fitting, matrix version)
We define a column vector 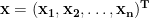
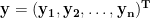

Anticipating the more general fitting problem, we will give our unknown parameters the names 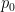
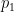

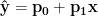
and the residuals can be expressed as 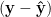
Let’s define a parameter vector 

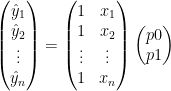
or 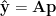
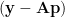
Recall that for any vector 
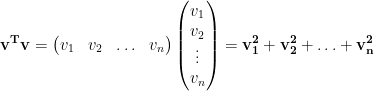
So the total squared residual E can be written as
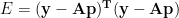
Expanding a product like this in linear algebra isn’t that different from ordinary algebra, using the Distributive Law (you may have learned the technique called FOIL or First, Outer, Inner, Last). The difference in matrix expressions is that you should keep products in the order they occurred because AB is not in general the same as BA.
We also need the property that the transpose of a product reverses the order of multiplication, i.e., that 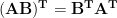

![\displaystyle E = (\bf{y}^T - \bf{p^TA^T}) (\bf{y} - \bf{Ap}) \\[6pt] = \bf{y^Ty} - \bf{y^TAp} - \bf{p^TA^Ty} + \bf{p^TA^TAp}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+E+%3D++%28%5Cbf%7By%7D%5ET+-+%5Cbf%7Bp%5ETA%5ET%7D%29+%28%5Cbf%7By%7D+-+%5Cbf%7BAp%7D%29+%5C%5C%5B6pt%5D+%3D+%5Cbf%7By%5ETy%7D+-+%5Cbf%7By%5ETAp%7D+-+%5Cbf%7Bp%5ETA%5ETy%7D+%2B+%5Cbf%7Bp%5ETA%5ETAp%7D+&bg=ffffff&fg=000&s=0&c=20201002)
Our vectors such as 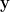
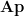
The middle two terms are transposes of each other, but since they are scalars, the transposes are equal, representing the same number. So we can combine them.
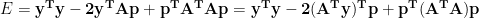
We want to minimize this with respect to 
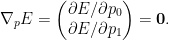
The first term is constant with respect to 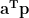



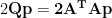
(For proofs of those gradients, see this post)
Thus the least squares solution for
![\displaystyle -2\bf{A^Ty} + 2\bf{(A^TA)p} = 0 \\[8 pt] \bf{(A^TA)p} = \bf{A^Ty}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+-2%5Cbf%7BA%5ETy%7D+%2B+2%5Cbf%7B%28A%5ETA%29p%7D+%3D+0+%5C%5C%5B8+pt%5D+%5Cbf%7B%28A%5ETA%29p%7D+%3D+%5Cbf%7BA%5ETy%7D+&bg=ffffff&fg=000&s=0&c=20201002)
This is a linear system of equations for 
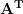
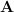

This is a general result. We started by asking what vector 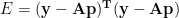
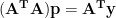
We often in linear algebra run into overdetermined systems (more equations than unknowns) of the form 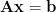
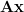

As we’ll see below, a much wider class of problems than linear regression fits this framework, and all those problems can be solved the same way. Because the equations are a linear system in terms of the unknown parameters, all such problems are considered linear least-squares.
The system 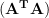

But both those languages also have the built-in capability to find the least-squares solution of an overdetermined system. Python has numpy.linalg.lstsq, and Matlab’s backslash operator will calculate the least-squares solution if the system is overdetermined. So in fact all you have to do is construct
To summarize, the way to do linear regression with linear algebra is:
- Create the 2-column matrix
values.
- Create a column vector
values.
- If your computer environment has a least-squares system solver, use it to find the least squares solution
.
- Otherwise, compute
and
- The elements of
Here is the Python code that performed the fit and plotted the results that appear at the top of this page. This code is modeled from the example code at https://numpy.org/doc/stable/reference/generated/numpy.linalg.lstsq.html.
A = np.vstack([np.ones(len(x)),x]).T
p = np.linalg.lstsq(A, y, rcond=None)[0]
plt.plot(x, y, 'o', label='Original data', markersize=10)
plt.plot(x, p[1]*x + p[0], 'r', label='Fitted line')
plt.legend()
plt.show()Notice that the actual regression only took two lines here. The other four lines are to generate the plot.
General Linear Least Squares
All of the method above is based on the equation 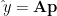

We can do this as long as our model has the form

i.e., a sum of 

This has the matrix representation 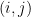



For linear regression, we have 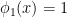



But it is much more general than that, since the 
- Create the r-column matrix
- Create a column vector
- If your computer environment has a least-squares system solver, use it to find the least squares solution
- Otherwise, compute
- The elements of
Examples of the general method
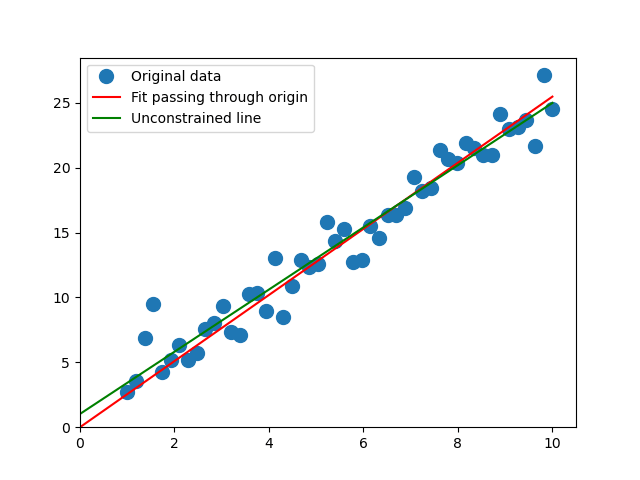
Line constrained to go through the origin
Sometimes we want a line where the y-intercept is forced to be 0. In this case, there’s only one parameter, the slope. It’s a little bit of overkill to use a computer linear algebra system to solve this problem, but we can still take advantage of the equations to immediately write down the solution.
Since we only have one function 
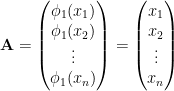
Then 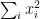
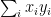
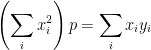
so
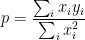
is the optimal slope. The figure below shows a fit using this model, compared to an ordinary linear regression with a nonzero y-intercept.
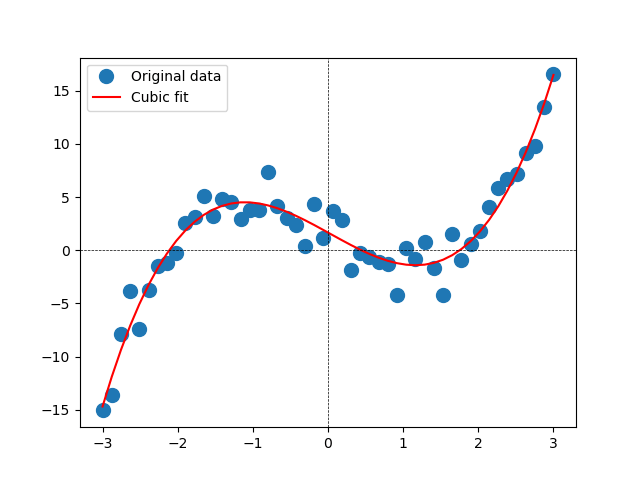
Cubic polynomial
The model here is 
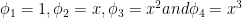
Again we use Python’s numpy.linalg.lstsq() to calculate the least-squares solution to
A = np.vstack([np.ones(len(x)),x,x*x,x**3]).T
p = np.linalg.lstsq(A, y, rcond=None)[0]The result is shown in the figure below.
Sinusoid
If we are trying to fit a model of the form 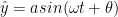
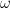
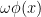
However, despite the fact that the phase shift 
![\displaystyle sin(a + b) = sin(a) cos(b) + cos(a) sin(b) \\ a sin(\omega t + \theta) = [a cos(\theta)] sin(\omega t) + [a sin(\theta)] cos(\omega t)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+sin%28a+%2B+b%29+%3D+sin%28a%29+cos%28b%29+%2B+cos%28a%29+sin%28b%29+%5C%5C+a+sin%28%5Comega+t+%2B+%5Ctheta%29+%3D+%5Ba+cos%28%5Ctheta%29%5D+sin%28%5Comega+t%29+%2B+%5Ba+sin%28%5Ctheta%29%5D+cos%28%5Comega+t%29+&bg=ffffff&fg=000&s=0&c=20201002)
So we will use a model with 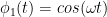
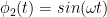
The result is shown below. The original data had a frequency of 2 Hz, so 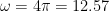
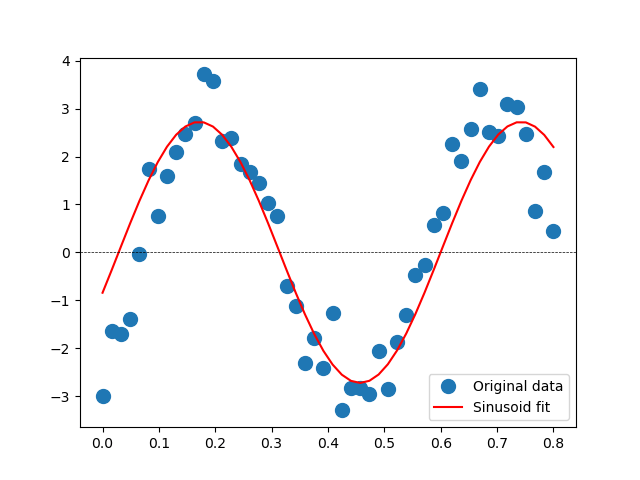
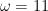 was used (actual value 12.57)
was used (actual value 12.57)
Leave a comment