This seems kind of esoteric but it’s the basis for really simplifying some complicated mathematics, like the general theory of least squares. It’s well worth working through if you’re going to be doing the linear algebra version of least squares or multivariable optimization.
The two main results proved as theorems below:
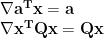
Definitions
In the expressions below, 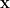


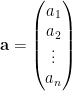
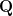
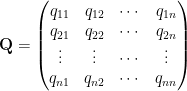
with 
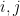
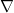
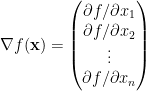
Gradient of linear function
Theorem: 
Proof: To see this, just work out the expression in terms of the individual components.



Thus

General quadratic function
Before examining its gradient, let’s examine some properties of the expression 
The most general quadratic function of the 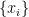

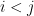


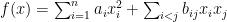
Now let’s examine the expression 
First, note that 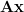
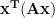

![\bf{x^TAx} = \frac{1}{2} \left ( \bf{x^TAx} + \bf{x^TA^Tx} \right ) \\[6 pt] = \frac{1}{2} \bf{x^T} (\bf{Ax} + \bf{A^Tx}) \\[6 pt] = \frac{1}{2} \bf{x^T} (\bf{A} + \bf{A^T}) \bf{x} \\[6 pt] = \bf{x^T} \left [ \frac{1}{2}(\bf{A} + \bf{A^T}) \right ] \bf{x}](https://s0.wp.com/latex.php?latex=%5Cbf%7Bx%5ETAx%7D+%3D+%5Cfrac%7B1%7D%7B2%7D+%5Cleft+%28+%5Cbf%7Bx%5ETAx%7D+%2B+%5Cbf%7Bx%5ETA%5ETx%7D+%5Cright+%29+%5C%5C%5B6+pt%5D+%3D+%5Cfrac%7B1%7D%7B2%7D+%5Cbf%7Bx%5ET%7D+%28%5Cbf%7BAx%7D+%2B+%5Cbf%7BA%5ETx%7D%29+%5C%5C%5B6+pt%5D+%3D+%5Cfrac%7B1%7D%7B2%7D+%5Cbf%7Bx%5ET%7D+%28%5Cbf%7BA%7D+%2B+%5Cbf%7BA%5ET%7D%29+%5Cbf%7Bx%7D+%5C%5C%5B6+pt%5D+%3D+%5Cbf%7Bx%5ET%7D+%5Cleft+%5B+%5Cfrac%7B1%7D%7B2%7D%28%5Cbf%7BA%7D+%2B+%5Cbf%7BA%5ET%7D%29+%5Cright+%5D+%5Cbf%7Bx%7D+&bg=ffffff&fg=000&s=0&c=20201002)
The matrix 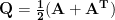


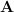
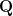
Finally, let’s expand 
The i-th element of 

So
![\bf{x^TQx} = \sum_{i=1}^n x_i (\bf{Qx})_i \\[6 pt] = \sum_{i=1}^n \sum_{j=1}^n x_i q_{ij} x_j](https://s0.wp.com/latex.php?latex=%5Cbf%7Bx%5ETQx%7D+%3D+%5Csum_%7Bi%3D1%7D%5En+x_i+%28%5Cbf%7BQx%7D%29_i+%5C%5C%5B6+pt%5D+%3D+%5Csum_%7Bi%3D1%7D%5En+%5Csum_%7Bj%3D1%7D%5En+x_i+q_%7Bij%7D+x_j+&bg=ffffff&fg=000&s=0&c=20201002)
which we can break into diagonal and off-diagonal terms
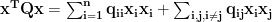
Now note in the second sum that every combination of distinct i and j occurs twice, once with 
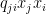



Comparing to the general quadratic function at the top of this section, we can see that any such expression can be written in the form 
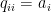

Gradient of a general quadratic
And now we can attack our final gradient calculation.
Theorem: 
Proof:
Note that 
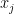


So the i-th element of the gradient vector is
![\frac{\partial}{\partial {x_i}} \bf{x^TQx} = \frac{\partial}{\partial {x_i}}\sum_{i=1}^n q_{ii} x_i^2 + \frac{\partial}{\partial {x_i}}\sum_{i, j, i < j} 2 q_{ij} x_i x_j \\[6 pt] = 2 q_{ii} x_i + \sum_{j \neq i} 2 q_{ij} x_j \\[6 pt] = 2 \sum_{j=1}^n q_{ij} x_j \\[6 pt] = 2 (\bf{Qx})_i](https://s0.wp.com/latex.php?latex=%5Cfrac%7B%5Cpartial%7D%7B%5Cpartial+%7Bx_i%7D%7D+%5Cbf%7Bx%5ETQx%7D+%3D++%5Cfrac%7B%5Cpartial%7D%7B%5Cpartial+%7Bx_i%7D%7D%5Csum_%7Bi%3D1%7D%5En+q_%7Bii%7D+x_i%5E2+%2B+++%5Cfrac%7B%5Cpartial%7D%7B%5Cpartial+%7Bx_i%7D%7D%5Csum_%7Bi%2C+j%2C+i+%3C+j%7D+2+q_%7Bij%7D+x_i+x_j+%5C%5C%5B6+pt%5D+%3D+2+q_%7Bii%7D+x_i+%2B+%5Csum_%7Bj+%5Cneq+i%7D+2+q_%7Bij%7D+x_j+%5C%5C%5B6+pt%5D+%3D+2+%5Csum_%7Bj%3D1%7D%5En+q_%7Bij%7D+x_j+%5C%5C%5B6+pt%5D+%3D+2+%28%5Cbf%7BQx%7D%29_i+&bg=ffffff&fg=000&s=0&c=20201002)
and it follows that

Leave a comment